To import subtitles you need to specify the structure of your script using groups.
Make sure the import tab is visible while modifying the import parameters. In this tab you can see how your script is being interpreted.
The preview tab contains 3 columns: text, blocks, subtitles.
In this tab you can also specify the file you want to use for testing.
Clean up
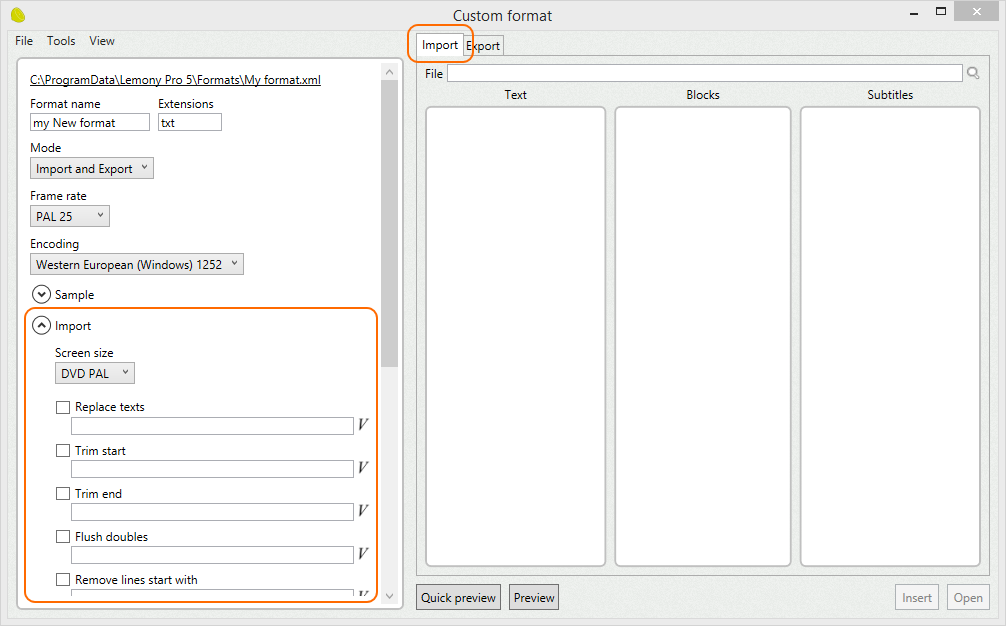
The first step is to load the text file and remove unnecessary data.
Some files contain garbage, and it is a good idea to remove it, for example, double spaces, comments, extra tabs, empty lines, and more.
You can use the options in the import parameters to replace texts, remove empty lines, trim characters, and more.
In the text column you can see how your raw text look like.
This is also useful to see if the selected encoding is decoding the file properly.
If your file has a simple structure, you can try to use menu Tools/Analyze input text. It analyzes your text and tries to do all the job below automatically.
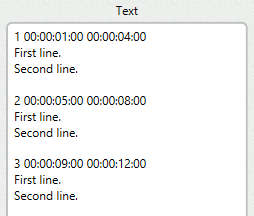
Blocks
The next step is to indicate which text lines (text blocks) conform the subtitles.
You need to specify the structure of your script using regular expressions or variables.
For this example, enter the following text in the block start field.
{ValueInteger} {HMSF}
It indicates how to find the beginning of a subtitle: it starts with a value (the index), a blank space, and a timecode in HMSF format.
In the blocks column you can see how the subtitles are recognized.
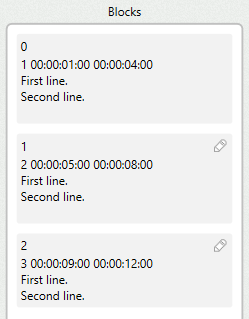
Fields
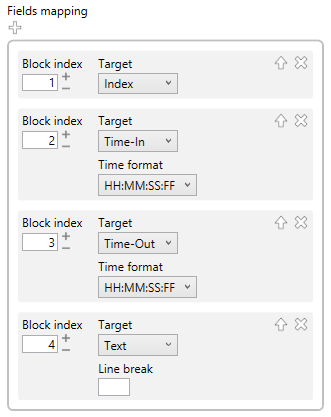
Now you need to indicate the structure of each subtitle, to be able to extract the information.
For this example, enter the following text in the fields parsing field.
{ValueInteger} {HMSF} {HMSF}
{TextLines}
It indicates that the subtitle consist of a value (the index), a blank space, a timecode in HMSF format, a blank space and another timecode, followed by the text lines.
In the blocks column you can see how the first subtitle is segmented in fields.
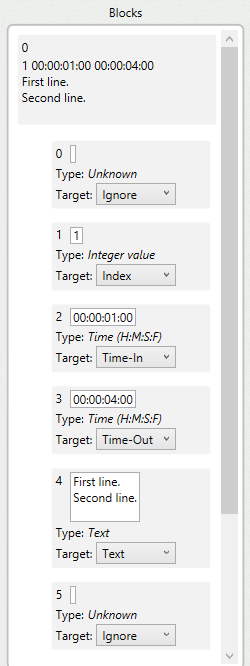
As you can see, the field #0 and #5 are empty.
Field #1 contains the index. Field #2 contains the time-in, etc.
In the import parameters you can specify how to interpret each field.
You can ignore the empty fields (which usually are the first and last ones) and just focus on the ones with information.
In the subtitles column you can see how your imported subtitles look like.